
Benchmarking Basics
Benchmarks are a standard point of reference used to compare similar things. There are several ways to benchmark the performance of a solution. This post goes over the basic concepts of performance testing and provides some general best practices for benchmarking a Hyper Converged Infrastructure (HCI) solution.
Benchmarking in General
Ideally, benchmarking a solution involves replicating an environment or leveraging an application simulator. Although these approaches are the best, it often requires an investment of time and money or the information required isn’t readily available. A more common benchmarking approach is to employ micro-benchmarks, which allow for targeted tests of specific code paths or I/O tasks. These tests are typically driven with a free, lightweight load-generator, making it a popular option for evaluating a solution’s performance.
There is an important difference between load-testing and stress-testing. Unlike load-testing, which is really about determining if a system meets some pre-determined requirements, stress-testing is performed with the goal of breaking a system. Although stress-testing can be used as a benchmark it is often unrepresentative of real workloads or use cases, so it’s important to have a clear goal in mind before beginning a testing cycle.
Not all Load-Generators Are the Same
Some tools provide a GUI, but these are often limited in functionality, while other tools provide more flexibility and a richer feature set, but no GUI. Throughout the years several tools have started to become common place. These tools include VDBench, FIO, IOMeter and DiskSpd.exe. When deciding on a load-generator, using a common one is always good idea.
Sometimes vendors will create a wrapper around these tools. For example, HCIBench is a wrapper around VDBench and VM IO Analyzer is a wrapper around IOMeter. Be aware that these wrappers can unintentionally limit the configurability of a test and may require manual editing to realize the full performance of a solution.
One of the most important things to consider when selecting a load-generator is the type of data it generates. Some tools will largely write null characters, or zeros. Modern storage will handle these as a special case, usually only writing minimal metadata. This will skew the outcome of both the write test and any subsequent read tests.
Chasing Numbers
Storage performance is often measured in throughput, which is the amount of work performed by a resource over a unit of time. This is most commonly measured in IOPS or as a data-rate. IOPS measures the rate of I/O’s per-second and the data-rate represents how much data was read or written. This is measured in some magnitude of bytes (B) per-second, like kilobytes per-second (KB/s) or megabytes per-second (MB/s). Note, throughput is not the same as bandwidth. Bandwidth refers to the raw link speed or the sustainable transmission rate and is annotated in bits (b).
Small I/O for More IOPS
When attempting to achieve a high number of IOPS a smaller I/O size, such as 4KB or 8KB, is preferred. Unlike physical drives which operate on sectors of 512B to 4KB, the atomic unit size for most storage vendors will be 4KB or 8KB, sometimes much larger. This means that a 512B I/O to storage will result in a 4KB or 8KB I/O on the storage device, respectively. This makes a difference when comparing max IOPS numbers between solutions, so some consideration should be given to how the system will actually be used when designing a test. If the expected average I/O is 8KB, the test should reflect that.
Large I/O for More Data
To achieve a high data rate a large I/O size is usually needed. It’s common to use an I/O size that falls somewhere between 64 KiB to 1 MiB. Generally, systems are more efficient when processing large chunks of data as this allows for more intelligent decisions around data placement, scheduling and batching.
The More the Merrier
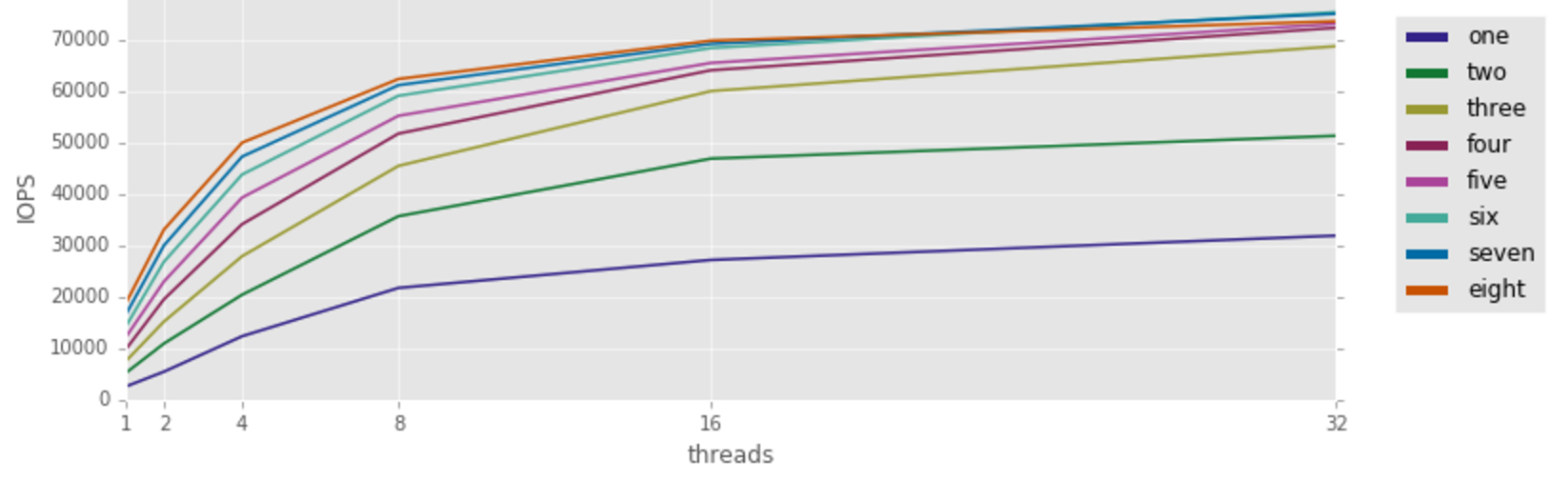
Concurrent workloads performed in parallel are crucial to realizing the most throughput possible. Concurrency refers to number of outstanding requests in flight where parallelism describes the simultaneous execution of those tasks. The throughput achieved will have a direct relationship with both of these variables, more concurrency results in more throughput until the system is operating at its full potential. These workloads are also more realistic, especially for HCI solutions that will house multiple VMs with various workloads simultaneously. Observations of real-world workloads have shown that, on average, there are typically four outstanding operations per I/O device, however, this can vary greatly by application.
With most load-generators the parallelism can be controlled by altering the number of devices or files that I/O is simultaneously being performed against. Concurrency is usually controlled with a test variable. Depending on the tool, this variable may be referenced as iodepth, outstanding I/O (OIO) or threads. Here’s a nifty plot that helps illustrate the importance of both concurrency and parallelism.
Number of Parallel Devices and Concurrency (Threads) Vs. IOPS
What really matters
Often times, testing methodologies become conflated and the line between load–testing and stress-testing blurs. The focus becomes throughput driven using unrealistic workloads with no bearing on user experience. This pitfall can be avoided by defining the requirements beforehand and focusing on response time while performing fix-rate tests.
Remember that load-generators are far more efficient at pushing I/O than real applications and real applications usually involve some think or processing time of their own. Avoid blindly testing by taking the time to understand the solution requirements and expected growth.
Understanding the requirements from a I/O and response time perspective to evaluate a potential solution, it’s likely any enterprise ready solution meets your I/O requirements.
Here are a few best practices when running load generators:
- Use raw devices. This will by-pass the guest’s File System (FS) cache and mitigates the impact of any Guest FS defects. Most business critical applications, like DBs, manage their own cache, plus, by-passing the FS cache puts the strain on the I/O path.
- Scale-up by using multiple virtual-disks per-node. This can be done with one VM that has multiple virtual-disks or multiple VMs with a single virtual disks.
- Scale-out by leveraging resources across the entire solution. Unlike tradition SAN, the host is typically a boundary for compute and memory resources.
- Use realistic block sizes. Applications and Filesystems make an effort to coalesce, or batch small I/O, into larger I/O for efficiency, 4KiB I/O sizes are actually not a common occurrence.
- If the solution combines SSDs and HDDs, size the working set to the SSD tier. Hybrid solutions are designed to keep the hottest data in the hot-tier, however, load generators can easily outpace the background process used to manage the data.
- Pre-populate the data. Only fill as much as much data as necessary to perform the test. This helps mitigate the ILM dependency.
- Validate that the testing tool does not write zeros (null characters)
- If using diskspd, use the –Z flag
- Don’t use SQLIO and avoid uncommon load generators